NLP Text Similarity, how it works and the math behind it
Have a look at these pairs of sentences, which one of these pairs you think has similar sentences?

You might be confident about the first two, but not so much about the last two. In reality, you’re right as the sentences in the first two pairs talk about the same thing (independently) and so are quite similar. However, the sentences in last two pairs talk about very different things and hence will not be seen as similar sentences.
Surprisingly, the opposite is true for NLP models. According to the way that text similarity works in NLP, the sentences in last two pairs are very much similar but not the ones in first two! 😮
Before you start judging the ability of NLP, let’s look at how it works and the math behind it. So, let’s see how the machine sees these sentences!
Sentence 1: “Global warming is here”
Sentences 2: “Ocean temperature is rising”
For these two to be similar, even from the machine’s perspective, you’ll need to explore a whole new dimension of semantic analysis, according to which these two sentences are quite similar. Click here and type in the two sentences.
Now, coming back to our NLP model, it’s time we crack it!
STEP 1: Pick only the unique words from the two sentences, which’d equal 7.
Unique Words: global, warming, is, here, ocean, temperature, rising
STEP 2: Count the number of occurrences of unique words in each of the sentences
Analysis of sentence 1global, 1
warming, 1
is, 1
here, 1
ocean, 0
temperature, 0
rising, 0
Analysis of sentence 2global, 0
warming, 0
is, 1
here, 0
ocean, 1
temperature, 1
rising, 1
The easy part is over and before we proceed, you must know that NLP’s text similarity works on the basis of cosine similarity. Cosine similarity is basically the cosine of the angle between two vectors. So, we want to convert the sentences into two vectors, which we’ve already done!
Vector of sentence 1: [ 1, 1, 1, 1, 0, 0, 0 ]
Vector of sentence 2: [ 0, 0, 1, 0, 1, 1, 1]
Let’s visualize the vectors.
Do note that, in our case we have a 7D vector and because it’s not possible to visualize a 7D vector, I’ll be showing you two 3D vectors and explain the working.
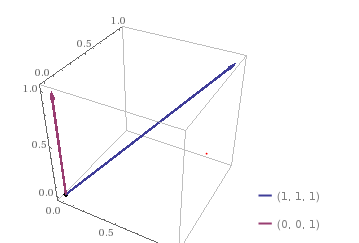
So, here we have two 3D vectors [ 1, 1, 1 ] and [ 0, 0, 1 ]. You can imagine these vectors as 2 sentences with 3 unique words in total. Here, [ 1, 1, 1 ] would mean that all 3 unique words occur once in the first sentence while [ 0, 0, 1 ] would mean that only the 3rd unique word occurs once in the second sentence.
We’re interested only in the angle between these two vectors. The closer the two lines are, the smaller will be the angle and hence, similarity increases. So, If any two sentences are perfectly similar you’d see only one line in the 3D space, as the two lines would overlap each other.
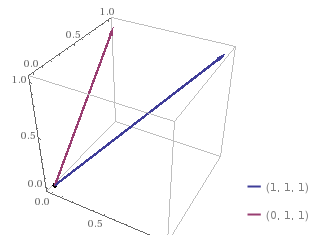
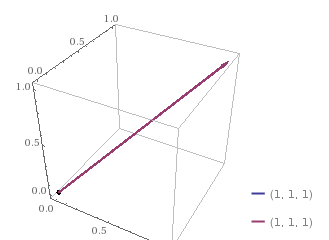
I hope you understand the idea of what we’re trying to achieve here or what NLP is trying to do. So, let’s get back to our original vectors and calculate the cosine angle between the two. Our vectors:
Vector of sentence 1: [ 1, 1, 1, 1, 0, 0, 0 ]
Vector of sentence 2: [ 0, 0, 1, 0, 1, 1, 1]
Measuring the angle between 2 vectors
It’s no rocket science, all you need to know is this formula:
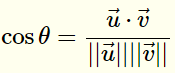
In the numerator, we have the dot product of the vectors and in the denominator, we have the product of the lengths of the two vectors.
- Let’s find out the dot product for our case:
The Formula -> (u1 * v1) + (u2 * v2) + ….. + (un * vn)
That’d be -> (1*0) + (1*0) +(1*1) +(1*0) +(1*0) +(1*0) +(1*0) = 1 - Find the length of the two vectors:
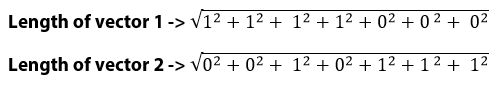
So, now we have to calculate: 1 / 4 which equals 0.25
To conclude, according to NLP text similarity, the two sentences “Global warming is here” and “Ocean temperature is rising” are only 25% similar which is completely opposite to what the semantic analysis would show.
Now, let’s quickly perform the same steps for one more pair of sentences:
Sentence 1: “This place is great”
Sentences 2: “This is great news”
Unique Words: this, is, great, place, news
Vector of sentence 1: [ 1, 1, 1, 1, 0 ]
Vector of sentence 2: [ 1, 1, 1, 0, 1 ]
Put these vectors into the cosine formula, and you get the value 0.75, meaning a similarity of 75%
Do note that, the greater the value smaller is the angle and more similar are the sentences.
So, next time when you think of using NLP Text Similarity in your project, you’d know its true purpose and how it is different from Semantic Analysis.
CHEERS!

Comments ()